
 Go语言零拷贝技术完全指南
Go语言零拷贝技术完全指南
# 前言
零拷贝(Zero-Copy)是高性能编程中的关键技术,它通过避免不必要的数据复制,可以显著提升I/O密集型应用的性能。本文将深入探讨:
- 零拷贝的核心原理与优势
- Go语言中实现零拷贝的三种主要方式
- 实际场景中的性能对比数据
- 如何根据业务场景选择最佳方案
通过本文,你将掌握如何在自己的项目中应用这些技术来提升性能。
# io.CopyBuffer
在读写时使用 io.Reader 和 io.Writer 接口时,可以使用 io.CopyBuffer 来提供重复使用的缓存区,避免了重复的分配中间的缓存。
func StreamData(src io.Reader, dst io.Writer) error {
buf := make([]byte, 4096) // Reusable buffer
_, err := io.CopyBuffer(dst, src, buf)
return err
}
1
2
3
4
5
2
3
4
5
# 高效数据访问切片
切片的底层是一个数组,所以基于该数组返回一个切片可以减少内存的拷贝,而不是将切片拷贝到一个新的切片中
func process(buffer []byte) []byte {
return buffer[128:256] // returns a slice reference without copying
}
1
2
3
2
3
Benchmark
针对显示复制和零复制切片的性能基准测试比较
func BenchmarkCopy(b *testing.B) {
data := make([]byte, 64*1024)
for range b.N {
buf := make([]byte, len(data))
copy(buf, data)
}
}
func BenchmarkSlice(b *testing.B) {
data := make([]byte, 64*1024)
for range b.N {
_ = data[:]
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
运行结果如下,BenchmarkCopy 每次都会分配新的内存,并进行数据的复制操作,而 BenchmarkSlice都是对相同的数组进行切片,没有任何的分配内存和复制数据的操作,BenchmarkSlice无论是运行还是内存上都优于 BenchmarkCopy
$ go test -bench=. -benchmem .
goos: darwin
goarch: arm64
pkg: main/demo
cpu: Apple M4 Pro
BenchmarkCopy-12 356439 3546 ns/op 65536 B/op 1 allocs/op
BenchmarkSlice-12 1000000000 0.2336 ns/op 0 B/op 0 allocs/op
PASS
ok main/demo 2.918s
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# mmap
正常读取文件时,是需要将磁盘中的文件读取到内核空间,再复制到用户空间进行访问。
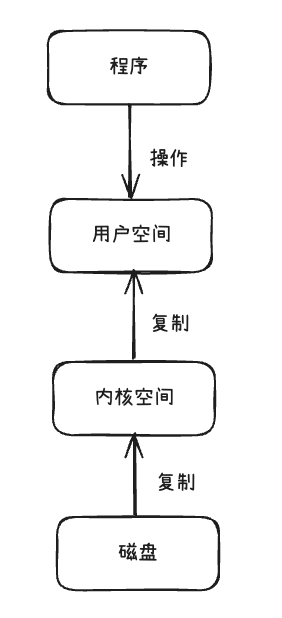
而使用mmap的方式,是直接将磁盘中的文件映射到内存中直接访问,减少了将内核空间与用户空间数据的复制。
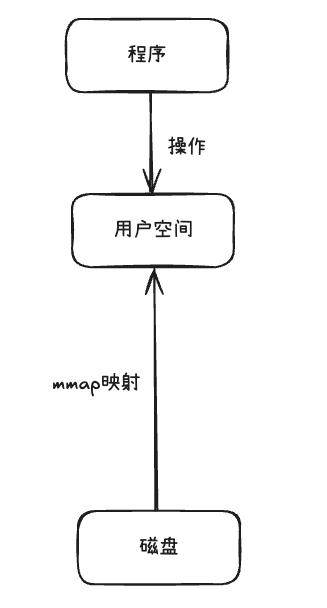
代码示例
import "golang.org/x/exp/mmap"
func ReadFileZeroCopy(path string) ([]byte, error) {
r, err := mmap.Open(path)
if err != nil {
return nil, err
}
defer r.Close()
data := make([]byte, r.Len())
_, err = r.ReadAt(data, 0)
return data, err
}
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
基准测试
使用 os.Open 和 mmap.Open 对 5M 文件的读取性能的基准测试。
func BenchmarkReadWithCopy(b *testing.B) {
f, err := os.Open("./5MB.bin")
if err != nil {
b.Fatalf("failed to open file: %v", err)
}
defer f.Close()
buf := make([]byte, 4*1024*1024) // 4MB buffer
for range b.N {
_, err := f.ReadAt(buf, 0)
if err != nil && err != io.EOF {
b.Fatal(err)
}
}
}
func BenchmarkReadWithMmap(b *testing.B) {
r, err := mmap.Open("./5MB.bin")
if err != nil {
b.Fatalf("failed to mmap file: %v", err)
}
defer r.Close()
buf := make([]byte, r.Len())
for range b.N {
_, err := r.ReadAt(buf, 0)
if err != nil && err != io.EOF {
b.Fatal(err)
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
运行结果如下,使用mmap比标准读要快不少,内存申请上也要少。
$ go test -bench=. -benchmem .
goos: darwin
goarch: arm64
pkg: main/demo
cpu: Apple M4 Pro
BenchmarkReadWithCopy-12 13136 90918 ns/op 319 B/op 0 allocs/op
BenchmarkReadWithMmap-12 19350 65262 ns/op 270 B/op 0 allocs/op
PASS
ok main/demo 7.067s
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 总结
根据测试结果,我们得出以下结论:
缓冲区重用:
- 使用
io.CopyBuffer重用缓冲区 - 适合流式数据传输场景
- 使用
切片操作:
- 优先使用切片引用而非完整复制
- 特别适合大块数据处理
文件读取:
- 大文件处理优先考虑mmap
- 注意mmap的内存映射特性
适用场景:
- 高吞吐量网络应用
- 大文件处理
- 内存敏感型应用
记住:零拷贝虽好,但也要考虑代码可读性和维护成本,在性能关键路径上使用效果最佳!
上次更新: 2025/06/14, 16:16:07